
La Inteligencia Artificial (IA) es la tecnología computacional que busca emular las funciones cognitivas del cerebro humano tales como como razonamiento, procesamiento cognitivo, reconocimiento de lenguaje natural, planificación, entre otros.
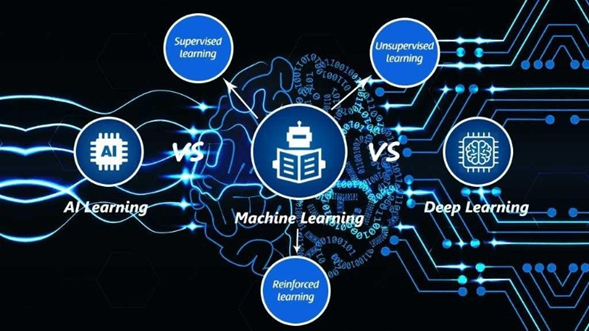
Dentro de lo que es la Inteligencia Artificial, existe un subconjunto de algoritmos que busca entrenar a las máquinas para que aprendan. Se les conoce como aprendizaje automatizado o Machine Learning (ML) Los modelos de Machine Learning buscan patrones en los datos para tratar de sacar conclusiones como lo haría el cerebro humano. Cuando las conclusiones a las que llega son suficientemente buenas, aplica el mismo modelo, o los mismos algoritmos para tratar de sacar conclusiones acertadas de un nuevo conjunto de datos. Dentro del área de análisis de datos, el Machine Learning pertenece al área conocida como análisis predictivo.
“Machine Learning es un campo de la ciencia que explora el desarrollo de algoritmos que pueden aprender y hacer predicciones sobre los datos.
La principal diferencia con otros algoritmos comunes es la pieza de “aprendizaje”. Los algoritmos de Machine Learning NO son series de procesos ejecutados en serie para producir un resultado predefinido.
En su lugar, son una serie de procesos que buscan “aprender” patrones de eventos pasados y construir funciones que pueden producir buenas predicciones, con un grado de confianza”.
Artur Samuel, 1959
Existen cuatro tipos de Aprendizajes Automatizados:
1. El aprendizaje supervisado, que es cuando un ser humano genera las primeras hipótesis del modelo, y luego va ajustando el mismo con base en los resultados. Utiliza técnicas estadísticas como la regresión, que permiten generar proyecciones del voto, o de las ventas de una empresa. Y la clasificación en grupos, como por ejemplo por tipo de clientes potenciales, o simpatizantes de una idea o partido político.
2. El aprendizaje no supervisado. En este caso se deja sola a la computadora analizar los datos y dejarla descubrir la estructura de los datos mediante la asociación estadística de los mismos. Un ejemplo es el análisis de conglomerados o Cluster Analysis, que permite segmentar clientes por tipos de preferencia, o votantes por tipos de demandas sociales o temas de interés. También permite hacer reducciones en la dimensionalidad de los datos que los hace más manejables, por ejemplo mediante análisis de factores o Factor Analysis.
3. El aprendizaje reforzado:
4. El aprendizaje profundo: en inglés Deep Learning, se basa en el uso de redes neuronales y se utiliza para hacer reconocimiento de imagen, de voz, manejo automatizado de vehículos, etc. En años recientes es el tipo de aprendizaje automatizado que mayores aportaciones ha tenido.
El poder analítico que ha hecho posible el uso de la Inteligencia Artificial y la explosión del uso del Machine Learning y el Deep Learning, ha sido posible gracias a la confluencia de tres elementos.
1. El aumento exponencial que ha tenido el poder de procesamiento de datos en las últimas cinco décadas, siguiendo la ley de Moore. Él observó que la capacidad de procesamiento de los procesadores de datos de las computadoras se duplicaba cada dos años mientras que su precio se reducía en un 50%. Esta ley sigue vigente en la actualidad.
2. La expansión de la capacidad de almacenamiento de datos a niveles nunca imaginados. Mismos que actualmente viven en “la nube”. La nube está constituida por enormes granjas de servidores que ofrecen el servicio de almacenaje y procesamiento de datos de manera flexible, a saber, rentan solo el espacio de almacenamiento y la capacidad de procesamiento que requiere el cliente por el tiempo que lo requiere. Lo cual reduce el costo de su uso significativamente.
3. El surgimiento y la expansión mundial del Internet, lo que ha facilitado la comunicación de grandes cantidades de información que antes no existía. A lo que se le ha sumado la acumulación de información que proviene de detectores en diferentes cosas, como el teléfono inteligente, el reloj inteligente, los sensores de electricidad digitales, los sensores en maquinarias diversas, el seguimiento a través de GPS, etc. Este amplio conglomerado de sensores se conoce como el Internet de las cosas o Internet of Things (IoT).
Como resultado de lo anterior la cantidad de información almacenada y disponible para ser analizada e interpretada para su uso productivo es enorme. Cualquier acto humano, o como comportamiento de las cosas es registrado. Este boom de datos se le conoce como Big Data. Este se concibe como un conjunto de datos complejos, masivos y cambiantes cuyas características se refieren a partir de las cinco V’s: Valor (datos que tengan utilidad concreta; Variedad (que provienen de fuentes y formatos diferentes); Velocidad (datos que se generan y distribuyen rápidamente); Veracidad (son fiel retrato de la realidad a la que aluden) y Volumen (por la cantidad de datos que concentran). El tipo de análisis posibles al contar con estas cantidades masivas de datos han expandido el potencial del conocimiento a nuevas fronteras.
Y todo lo anterior ha derivado en una nueva revolución industrial, la llamada Cuarta Revolución Industrial, que apenas comienza y lo transformará todo: negocios, política, empleo, formas de transportarse, tipos de recreación, formas de relacionarse socialmente, etc. Cambios que ya están aquí y que se están dando de una manera vertiginosa e inexorable.